
Saturday
Oct092021
Congratulations to Ntombizodwa Makuyana
 Congratulations to Ntombizodwa Makuyana, for winning the Babraham Institute prize for best poster by a first year PhD student!
Congratulations to Ntombizodwa Makuyana, for winning the Babraham Institute prize for best poster by a first year PhD student!
A great start to a high potential PhD!
Becoming a Scientist

Virus Fighter
Build a virus or fight a pandemic!

Maya's Marvellous Medicine

Battle Robots of the Blood

Just for Kids! All about Coronavirus

Congratulations to Ntombizodwa Makuyana, for winning the Babraham Institute prize for best poster by a first year PhD student!
A great start to a high potential PhD!

Researchers identify the origin of potentially dangerous unstable cells
Key points:
By purifying cells using markers of instability, or following a two-step purification process, the researchers are able to produce a robust set of protective cells. Research in mice, published today by researchers at the Babraham Institute, UK and VIB-KU Leuven, Belgium, provides two solutions with potential to overcome a key clinical limitation of immune cell therapies. Cell therapy is based on purifying cells from a patient, growing them up in cell culture to improve their properties, and then reinfusing them into the patient. Professor Adrian Liston, Immunology group leader at the Babraham Institute, explained: “The leading use of cell therapy is to improve T cells so that they can attack and kill a patient’s cancer, however the incredible versatility of the immune system means that, in principle, we could treat almost any immune disorder with the right cell type. Regulatory T cells are particularly promising, with their ability to shut down autoimmune disease, inflammatory disease and transplantation rejection. A key limitation in their clinical use, however, comes from the instability of regulatory T cells – we just can’t use them in cell therapy until we make ensure that they stay protective”. By identifying the unstable regulatory T cells, and understanding how they can be purged from a cell population, the authors highlight a path forward for regulatory T cell transfer therapy. The study is published today in Science Immunology.
 T cells come in a large variety of types, each with unique functions in our immune system. “While most T cells are inflammatory, ready to attack pathogens or infected cells, regulatory T cells are potent anti-inflammatory mediators”, Professor Susan Schlenner, University of Leuven, explains. “Unfortunately this cell type is not entirely stable, and sometimes regulatory T cells convert into inflammatory cells, called effector T cells. Crucially, the converted cells inherit both inflammatory behaviour and the ability to identify our own cells, and so pose a significant risk of damage to the system they are meant to protect.”
T cells come in a large variety of types, each with unique functions in our immune system. “While most T cells are inflammatory, ready to attack pathogens or infected cells, regulatory T cells are potent anti-inflammatory mediators”, Professor Susan Schlenner, University of Leuven, explains. “Unfortunately this cell type is not entirely stable, and sometimes regulatory T cells convert into inflammatory cells, called effector T cells. Crucially, the converted cells inherit both inflammatory behaviour and the ability to identify our own cells, and so pose a significant risk of damage to the system they are meant to protect.”
The first key finding of this research shows that once regulatory T cells switch to becoming inflammatory, they are resistant to returning to their useful former state. Therefore, scientists need to find a way to remove the risky cells from any therapeutic cell populations, leaving behind the stable regulatory T cells. By comparing stable and unstable cells the researchers identified molecular markers that indicate which cells are at risk of switching from regulatory to inflammatory. These markers can be used to purify cell populations before they are used as a treatment.
![]()
In addition to this method of cell purification, the researchers found that exposing regulatory T cells to a destabilising environment purges the unstable cells from the mixture. Under these conditions, the unstable cells are triggered to convert into inflammatory cells, allowing the researchers to purify the stable cells that are left. “The work needs to be translated into human cell therapies, but it suggests that we might be best off treating the cells mean”, says Professor Adrian Liston. 
Establishing a thorough process to improve cell population stability in mice helps to lay the groundwork for improved immune cell therapies in humans, although the methods described in this work would require validation in humans before they were used in cell therapy trials. Tim Newton, CEO of Reflection Therapeutics, a Babraham Research Campus-based company designing cell therapies against neuro-inflammation and independent from the research, commented on the translational potential of the study: "This research makes a significant impact on regulatory T cell therapeutic development by characterising unstable subsets of regulatory T cells that are likely to lose their desirable therapeutic qualities and become pro-inflammatory. The successful identification of these cells is of great importance when designing manufacturing strategies required to turn potential T cell therapeutics into practical treatments for patients of a wide range of inflammatory disorders."
Read the full paper here.
Metrics, especially impact factor, have fallen badly out of favour as a mechanism for tenure review. There are good reasons for this - metrics have flaws, and journal impact factors clearly have flaws. It is important, however, to weigh up the pros and cons of the alternative systems that are being put in place, as they also have serious flaws.
To put my personal experience on the table, I've always been in institutes with 5 yearly rolling tenure. I've experienced two tenure reviews based on metrics, and two based on soft measures. I've also been a part of committees designing these systems, for several institutes. I've seen colleagues hurt by metric-orientated systems, and colleagues hurt by soft measurement systems. There is no perfect system, but I think that people seriously underestimate the potential harm of soft measurement systems.
Example of a metric-based system
When I first joined the VIB, they had a simple metric-based system. Over the course of 5 years, I was expected to publish 5 articles in journals with an impact factor over 10. I went into the system thinking that these objectives were close to unachievable, although the goals came along with serious support that made it all highly achievable.
For me, the single biggest advantage of the metric-based system was its transparency. It was not the system I would have designed, but I knew the goals, and more importantly I could tell when I had reached those goals. 3 years into my 5 year term I knew that I had met the objectives and that the 5 yearly-review would be fine. That gave me and my team a lot of peace of mind. We didn't need to stress about an unknowable outcome.
Example of a soft measurement system
The VIB later shifted to a system that is becoming more common, where output is assessed for scientific quality by the review panel, rather than by metrics. The Babraham Institute, where I am now, uses a similar system. Different institutes have different expectations and assessment processes, but in effect these soft measurement systems all come down to a small review panel making a verdict on the quality of your science, with the instruction not to use metrics.
This style of assessment creates an unknown. You really don't know for sure how the panel will judge your science until the day their verdict comes out. Certainly, they have the potential to save group leaders that would be hurt by metric-based systems, but equally they can fail group leaders who were productive but judged more harshly by biases introduced through the panel then by the peer-review they experienced by manuscript reviewers.
This in fact brings me to my central thesis: with either metrics or soft measurement systems, you end up having a small number of people read your papers and make their own judgement on the quality of the science. So let's compare how the two work in practice:
Metrics vs soft measurements
Under the metric-based system, essentially my tenure reviewers were the journal editors and external reviewers. For my metrics, I had to hit journals with impact factors about 10, which gives me around 10 journals to aim at in my field. I had 62 articles during my first 5 years, and let's say that the average article went to two journals, each with an editor and 3 reviewers. That gives me a pool of around 500 experts reviewing my work, and judging whether it is of the quality and importance worthy of hitting a major journal. There is almost certainly going to be overlap in that pool, and I published a lot more than many starting PIs, but it is not unreasonable to think that 100 different experts weighed in. Were all of those reviews quality? No, of course not. But I can say that I had the option to exclude particular reviewers, the reviewers could not have open conflicts of interest, the journal editor acted as an assessor of the review quality, and I had the opportunity to rebut claims with data. Each individual manuscript review is a reviewer roulette, a flawed process, but in aggregate it does create a body of work reviewed by experts in the field.
Consider now the soft measurement system. In my experience institutes reviewed all PIs at the same time. Some institutes do this with an external jury, with perhaps 10 individuals but maybe only 1-3 are actually experts on your topic. Other institutes do this with an internal jury, perhaps 3-5 individuals in the most senior posts. In each case, you have an extremely narrow range of experts, reviewing very large numbers of papers in a very short amount of time. In my latest review I had 79 articles over the prior 5 years. I doubt anyone actually read them all (I wouldn't expect them to). More realistically, I expect they read most of the titles, some of the abstracts, and perhaps 1-2 articles briefly. Instead, what would have heavily influenced the result is the general opinion of my scientific quality, which is going to be very dependent on the individuals involved. While both systems have treated me well, I have seen very productive scientists fall afoul of this system, simply because of major personality clashes with their head of department (who typically either selects the external board, or chairs the injury jury). Indeed, I have seen PIs leave the institute rather than be reviewed under this system, and (in my experience) the system has been a heavier burden on women and immigrants.
Better metrics
As part of the University of Leuven Department of Microbiology and Immunology board, I helped to fashion a new system which was built as a composite of metrics. The idea was to keep the transparency and objectivity of metrics, but to use them in a responsible manner and to ameliorate flaws. The system essentially used a weighted points score, building on different metrics. For publications in the prior 5 years, journal impact factor was used. For publications >5 years old, this was replaced by actual citations of your article. Points were given for teaching, Masters and PhD graduations, and various services to the institute. Again, each individual metric includes inherent flaws, and the basket of metrics used could have been improved, but the ethos behind the system was that by using a portfolio of weighted metrics you even out some of the flaws and create a transparent system.
The path forward
I hope it is clear that I recognise the flaws present in metrics, but also that I consider metrics to confer transparency and to be a valuable safeguard against the inevitable political clashes that can drive decisions by small juries. In particular, metrics can safe-guard junior investigators against the conflicts of interest that can dominate when a small internal jury has the power to judge the value of output. Just because metrics are flawed doesn't mean the alternatives are necessarily better.
In my ideal world (in the unlikely scenario that I ever become an institute director!), I would implement a two-stage review system, using 7 years cycles. The first stage would be metric-based, using a portfolio of different metrics. These metrics would be in line with institute values, to drive the type of behaviour and outputs that are desired. The metric would include provisions for parental or sick leave, built into the system. They would be discussed with PIs at the very start of review period, and fixed. Everything would be above board, transparent, and realistic for PIs to achieve. Administration would track the metrics, eliminating the excess burden of constant reviewing on scientists.
For PIs who didn't meet the metric-based criteria a second system would kick in. This second system would be entirely metric-free, and would instead focus on the re-evaluation of their contributions. By limiting this second evaluation to the edge cases, substantial resources could be invested to ensure that the re-evaluation was performed in as unbiased a manner as possible, with suitable safeguards. I would have a panel of 6 experts (paid for their time), 3 selected from a list proposed by the PI and 3 selected from a list proposed by the department head. Two internal senior staff would also sit on the panel, one selected by the PI and one selected by the department head. The panel would be given example portfolios of PIs that met the criteria of tenure-review, to bench-mark against. The PI would present their work and defend it. The panel would write a draft report and send it to the PI. The PI would then have the opportunity to rebut any points on the report, either in writing or as an oral defence, by the choice of the PI. The jury would then make a decision on whether the quality of the work met the institute objectives.
I would argue that this compound system brings in the best of both worlds. For most PIs, the metric-based system will bring transparency and will reduce both stress and paperwork. For those PIs that metrics don't adequately demonstrate their value, they get the detailed attention that is only possible when you commit serious resources to a review. Yes, it takes a lot of extra effort from the PI, the jury and the institute, which is why I don't propose it to run for everyone.
TLDR: it is all very well and good to celebrate when an institute says it is going to drop impact factors in their tenure assessment, but the reality is that the new systems put in place are often more political and subjective than the old system. Thoughtful use of a balanced portfolio of metrics can actually improve the quality of tenure review while reducing the stress and administrative burden on PIs.
 Adrian Liston
Adrian Liston
Coda: obviously I have my own opinion on what makes a good reviewing system. However when I am on a review panel, even when chairing a review panel, I explicitly follow the institution rules laid out for me. If given the chance I will try to convince them that rule changes will give better outcomes, but if the system says to ignore X, Y or Z, then I ignore X, Y or Z.
Adrian Liston
With regards to the Declaration on Research Assessment (DORA). While DORA has its heart in the right place, I believe they are wrong to suggest blanket bans on particular metrics. The striking thing about DORA is that while they accurately point out the flaws of particular metrics, they don't propose actual working alternatives. In practice, this results in an institution that has removed valuable tools from their tool-kit, without clear guidence on how to replace them. Specifically, some of the metrics preferred by DORA are less suitable for the job. For example, DORA prefers H-factor over IF, but H-factor is essentially correlated to seniority and is incredibly ill-suited to measuring a tenure-track PI who may have their key papers less than one year ago. They also suggest "assessing the scientific content", without any guidence on how to do so, and the potential pitfalls that institutions fall into when trying to do this. In short, DORA opened up an important debate, but is more proscriptive than helpful.
Adrian Liston
A note on perceived value and economic theory:
Part on my thesis here, is that the high perceived value of impact factor ends up driving actual value, regardless of the fragility of the original perception. Consider metrics to be like currency - the value of the currency lies in the common belief that it has value. The more widely shared that belief is, the more stable the currency is, which is why Bitcoin fluctuates wildely compared to the Euro.
How does this analogy work when applied to impact factor? Think of a new journal starting up, and imagine they accidently got given a really good impact factor, say 8.2. Just a glitch in the system, no real value. Authors looking for a high impact factor journal see this new journal, and submit quality work. Reviewers asked to review for a new journal check the impact factor and think it is legit. They mentally benchmark the submitted work against other 5-10 impact factor journals. A year later, that accidental impact factor has solidified into a genuine impact factor of 5-10. In other words, the more people who think that journal impact factor is a measure of quality, the better a measure of quality it becomes - regardless of how flawed the original calculation was.
Does my example seem overly speculative? It isn't. I've been on the board of new journals. They are desperate to get as high a starting impact factor as possible, precisely because it creates that long-lasting mental benchmark. The fact that journals try to game impact factors and advertise increases in impact factors shows that these mental benchmarks exist widely in the community and have real impacts on the quality of submissions and reviews.
In short, any metric that is widely perceived as being correlated with quality will start to become correlated with quality, just through economic theory. Regardless of how stupid that metric was to begin with.
Today I gave a talk on my career trajectory for the University of Turku, in Finland. Looking back on the things I did right and wrong at different stages of my career, and a little advice for the next generation of early career researchers:
An old talk I gave on my scientific career, with an emphasis on being a parent scientist and on my experience in seeing sexism in action in the academic career pathway:

 Key points:
Key points:
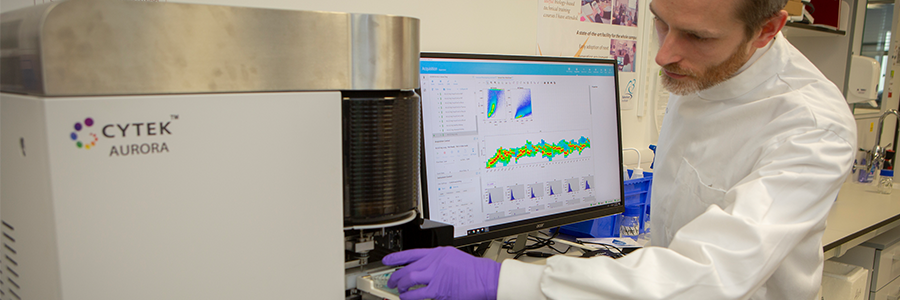
Flow cytometry is a key investigative tool used in biomedical research, allowing researchers to identify, separate and study cells according to their characteristics, often working with cell samples containing millions of cells at an analysis pace of a million cells per minute. Cell identification is achieved by labelling cells with fluorescent tags. As with personal gadgets and devices, innovation in molecular biology technologies isn’t standing still. Advances in flow cytometry have allowed scientists to gather data on a growing number of parameters, simultaneously detecting over 30 different tags at a time to allow more sophisticated analyses and much deeper levels of insight. However, while flow cytometry equipment has been updated, the accompanying computational requirements have received less attention, until now. AutoSpill, an algorithm developed by researchers at the Babraham Institute and the VIB Center for Brain Research, brings data processing in line with state-of-the-art machines, simplifying data analysis and increasing accuracy. The new technique is published in Nature Communications today.
Immunology programme senior group leader Prof. Adrian Liston, explained: "Flow cytometry is a foundational technology across many different biomedical research areas, and is a key diagnostic tool in immunology, haematology and oncology. Despite the technical progress over the past decades, the technology has been held back by the mathematical processing of the data. Our new approach reduces error by 100,000-fold, making research and diagnostics more accurate. The collaboration with FlowJo has enabled us to instantly reach 80,000 users. It is very gratifying to see computational biology have a direct and real impact on research and diagnostics."
Using multiple fluorescent signals raises a key issue in flow cytometry called spillover. Spillover occurs because each tag, called a fluorophore, emits light within a range of wavelengths, giving it a unique colour. When multiple fluorophores are used, the signals begin to overlap. To accurately distinguish between two distinct fluorophore signals, researchers must process their data to compensate. Because flow cytometry uses so many different colour tags on each cell, the spillover between colours quickly accumulates, limiting scientists’ power to draw reliable conclusions from their results. The processing of data to remove the spillover between the different colours, known as compensation, is necessary for all flow cytometry experiments. Current methods require many hours of manual work, but AutoSpill reduces the process to minutes.
Dr Rachael Walker, Head of the Institute Flow Cytometry facility, commented: “The new AutoSpill Fluorescence Compensation algorithm is a great tool for quick, simple and accurate compensation. It allows compensation to be accurately calculated on samples where the traditional algorithm is difficult to use. AutoSpill’s integration into the FlowJo post-acquisition software highlights the importance of this new compensation method.”
Another limitation of flow cytometry is autofluoresence, fluorescence produced naturally by cells. The removal of these artefacts by AutoSpill is particularly useful for cancer biologists as tumour cells are high in autofluorescence, which can confuse identification of the type of tumour cell present. By solving these sources of error, AutoSpill can help remove false positives from cell analyses, ensuring more accurate data interpretations.
AutoSpill is available through open source code and a freely-available web service. AutoSpill, and a complementary related tool, AutoSpread, are also available in FlowJo v.10.7. Dr John Quinn, Director of Science and Product Development, FlowJo added: “AutoSpill & AutoSpread have been a revelation for FlowJo users. Compensation has long been one of the most perplexing aspects of cytometry, with the most critical requirement being pristine compensation controls collected for each and every parameter in an experiment. Overall, the combination of these two tools makes compensation both easier and more robust. As an indicator of the popularity of this new approach, the webinar held in conjunction with Nature to introduce AutoSpill / AutoSpread in FlowJo has been viewed over 400 times after the initial live event. We at FlowJo believe the AutoSpill / AutoSpread approach will be the primary means of approaching compensation moving forward.”

